技術的保護策とプライバシーの課題
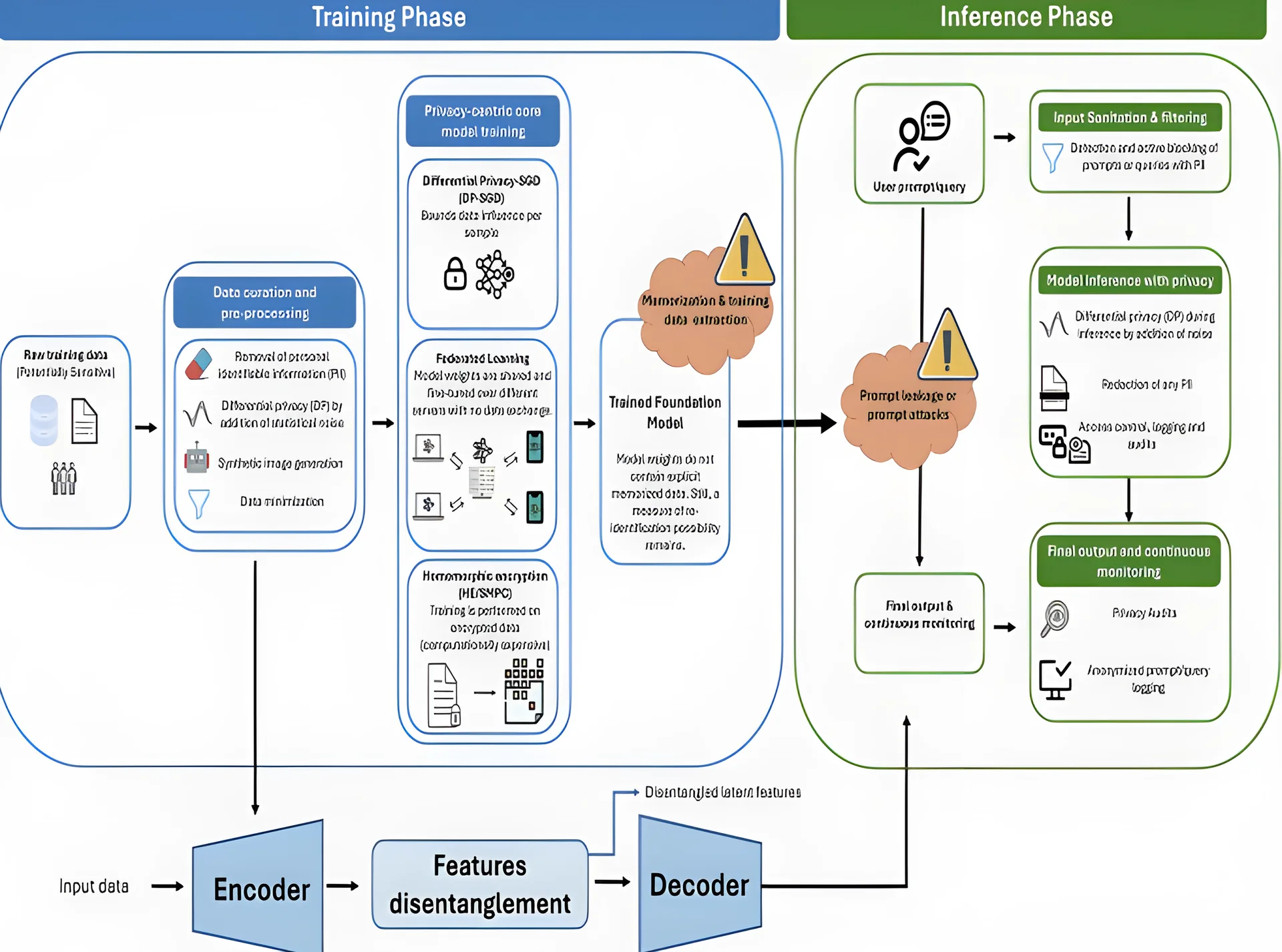
研究は、医療画像診断における基礎モデルの導入に伴う主な技術的課題として、モデルの出力と外部データセットを組み合わせた際に再識別リスクが生じる可能性を指摘している。研究者らは、現在の研究が多様性に欠けるデータセットを用いているため、現実的なプライバシーリスクを正確に反映していないと指摘している。
特徴の分離(feature disentanglement)などの技術的解決策が、臨床的に重要なパターンと識別可能な詳細を分離する方法として提案されている。この方法により、モデルは疾患のマーカーに注目しつつ、機密情報の暴露を最小限に抑えることができる。また、分散型学習(federated learning)の枠組みが、データの集中管理による漏洩リスクを低減する手段として検討されている。
合成データ生成と強固なプライバシー保証を組み合わせることで、個人の識別を守る一方でモデルの有用性を維持することができる。しかし、研究は、モデルの出力と外部データ源を組み合わせた際にプライバシー侵害が最も起こり得ると警告している。これは、実際のリスクを正確に評価し、緩和するための経験的シミュレーションと多様な訓練データセットの必要性を強調している。
政策と規制の枠組み
政策の観点から、研究はAI特有のリスクに対応するための法改正の必要性を強調している。米国のHIPAA(健康保険可搬性および責任法)は、基礎モデルの特異的な課題を考慮して見直しが必要かもしれない。同様に、EUのGDPR(一般データ保護規則)は、法的・公平・透明なデータ処理を義務付ける強固な枠組みを提供しており、個人は自身の個人情報をアクセス・訂正・削除・転送する権利を持つ。
最近制定されたEU AI Actは、医療関連のAIシステムにおけるデータプライバシーの重要性を強調し、AIアルゴリズムのリスクベース評価を導入している。この法は、高リスクシステムに対して特定の義務を課しており、バイアスや差別を排除することを要求している。また、汎用AIモデルの提供者には、トレーニングデータの概要、技術文書、リスク緩和戦略の開示が義務付けられている。
AI Actに加えて、2024年末に発表されたEUサイバーレジリエンス法(CRA)は、デジタル製品、特に医療ツールに対して厳格なセキュリティ要件を課している。CRAでは、製造業者がソフトウェアの材料リストを保持し、製品の脆弱性を対応し、24時間以内にインシデントを報告することを義務付けており、製品は重要度によって分類され、より重要なシステムには厳格な適合性評価が求められる。
学際的協力と実用例
研究は、規制機関、研究者、臨床医の間での学際的協力の重要性を強調し、AI駆動型医療における最適な実践を確立する必要性を指摘している。FMにおけるプライバシーと公平性の確保には、技術革新だけでなく、臨床医、データサイエンティスト、倫理学者、法務専門家との意図的な協力も必要である。
効果的な協力は、3つの核となる柱に構築されるべきである。モデル開発段階で専門家を巻き込む共同設計プロトコル、共同データ利用合意や倫理審査委員会などの共有ガバナンスフレームワーク、モデルの利用者と開発者間の継続的なフィードバックループ。これらの構造は、公平性の影響を反復的に評価し、緩和戦略が透明に報告されるようにする。
これらの原則が実際に適用された例として、希少な網膜神経変性疾患の進行を予測するプライバシー保護型基礎モデルを開発した多機関の眼科コンソーシアムが挙げられる。このモデルは、患者データを中央集約せずに複数の施設で分散学習によって訓練されている。
データはPII(個人識別情報)の除去、差分プライバシー変換、最小化により、必要な臨床的特徴のみを保持している。特徴分離モジュールにより、疾患に関連する信号と機密属性が分離され、汎用性が向上し、プライバシーリスクが低減されている。
推論段階では、モデルは識別可能な情報をブロックする入力クリーンアップを行い、差分プライバシー技術によって個々のデータの影響を制限している。この実際の応用例は、技術的およびガバナンス戦略がどのように運用されて、患者のプライバシーを守る一方で医療AIを前進させることができるかを示している。
規制の枠組みが継続的に進化する中、研究は再識別リスクを緩和するための包括的な戦略の必要性を強調している。特徴分離などの技術的保護策は、臨床的に重要な情報を分離するための優先事項である。






コメント
まだコメントはありません
最初にコメントしましょう